
近日,来自哥本哈根大学、苏黎世联邦理工学院等机构的研究人员提出了一种全新的多模态Few-shot 3D分割方法,并成功登上了ICLR 2025的Spotlight。这一研究成果为3D场景理解领域带来了新的突破,有望极大地降低对大量详细标注3D数据的依赖。

随着人形机器人、VR/AR以及自动驾驶汽车等技术的快速发展,对3D场景的精确理解变得越来越重要。然而,传统的全监督模型虽然在特定类别上表现出色,但其能力局限于预定义类别,每当需要识别新类别时,都必须重新收集并标注大量3D数据以及重新训练模型,这一过程既耗时又昂贵。
为了解决这一问题,Few-shot学习应运而生。它旨在利用极少量的示例样本使模型能够有效识别任意的全新类别,大大降低了新类适应的开销。然而,当前的研究大多局限于单模态点云数据,忽略了多模态信息的潜在价值。
针对这一空白,该研究团队提出了一种全新的多模态Few-shot 3D分割设定,并推出了创新模型——MultiModal Few-Shot SegNet(MM-FSS)。该模型能够融合文本、2D和3D信息,无需额外标注成本,即可让模型迅速掌握新类别。
在传统的Few-shot 3D点云语义分割(FS-PCS)任务中,模型的输入通常包含少量的支持点云及其对应的新类别标注,以及查询点云。模型需要借助支持样本中关于新类别的知识,在查询点云中完成新类别分割。而MM-FSS则引入了额外的文本和2D模态信息。其中,文本模态对应于支持样本中的目标类别/新类的名称,而2D模态则对应于与3D场景采集同步获得的2D图片。值得注意的是,2D模态仅用于模型预训练阶段,不要求在meta-learning和测试时作为输入。
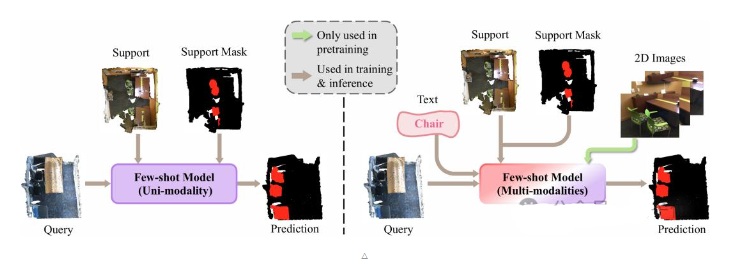
为了实现多模态信息的有效融合,MM-FSS在Backbone后引入了两个特征提取分支:跨模态特征头(IF Head)和单模态特征头(UF Head)。在预训练阶段,模型通过利用3D点云和2D图片数据对进行跨模态对齐预训练,使得IF Head学习到与2D视觉-语言模型对齐的3D特征。在Few-shot训练阶段,模型则分别利用IF Head和UF Head输出的特征计算出对应的特征相似度(correlations),并通过Multimodal Correlation Fusion(MCF)进行融合。此外,为了进一步利用文本模态中的语义信息,模型还设计了Multimodal Semantic Fusion(MSF)模块。
在测试阶段,为了缓解Few-shot模型对于训练类别的training bias,MM-FSS引入了Test-time Adaptive Cross-modal Calibration(TACC)机制。它利用跨模态的语义引导适应性地修正预测结果,实现更好的泛化。实验结果表明,MM-FSS在各类Few-shot任务中都实现了最佳性能,可视化结果也清楚表明了模型能够实现更优的新类分割。
这一研究成果不仅揭示了过往被普遍忽略的“免费”多模态信息对于小样本适应的重要性,还为未来的研究提供了宝贵的新视野。随着技术的不断发展,相信这一全新的多模态Few-shot 3D分割方法将在更多领域发挥重要作用。
该文章的第一作者为安照崇,目前在哥本哈根大学攻读博士学位。通讯作者为苏黎世联邦理工的孙国磊博士和南开大学的刘云教授。
感兴趣的读者可以访问论文链接(https://arxiv.org/abs/2410.22489)和代码仓库(https://github.com/ZhaochongAn/Multimodality-3D-Few-Shot)了解更多详情。
© 版权声明
文章版权归作者所有,未经允许请勿转载。









全新多模态Few-shot 3D分割方法登上ICLR 2025 Spotlight